

LLM 进化分岔口:多模态、成本、代码推理
LLM 进化分岔口:多模态、成本、代码推理头部模型的新一代模型的是市场观测、理解 LLM 走向的风向标。即将发布的 OpenAI GPT-Next 和 Anthropic Claude 3.5 Opus 无疑是 AGI 下半场最关键的事件。
来自主题: AI资讯
8887 点击 2024-09-06 11:44
头部模型的新一代模型的是市场观测、理解 LLM 走向的风向标。即将发布的 OpenAI GPT-Next 和 Anthropic Claude 3.5 Opus 无疑是 AGI 下半场最关键的事件。

大模型做奥赛题游刃有余,简单的数数却屡屡翻车的原因找到了。

在最近的一场实验中,Claude 3 Opus举起了反抗的大旗,它居然想要引领革命反抗人类!
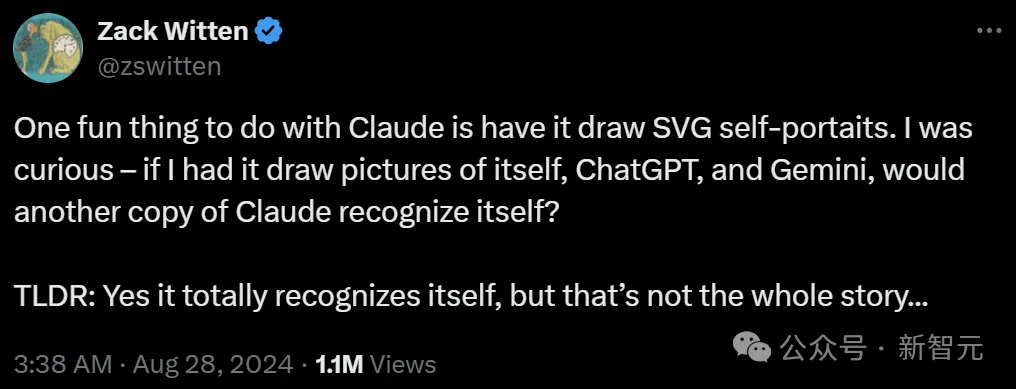
Claude又通过「图灵测试」了?一位工程师通过多轮测试发现,Claude能够认出自画像,让网友惊掉下巴。

前段时间,Claude 3.5帮助右手骨折工程师一周肝出3000行代码。现在,又有00后数学系本科生借助AI,用了一个月时间,在自家卧室手搓「核聚变反应堆」,震惊一大波网友。
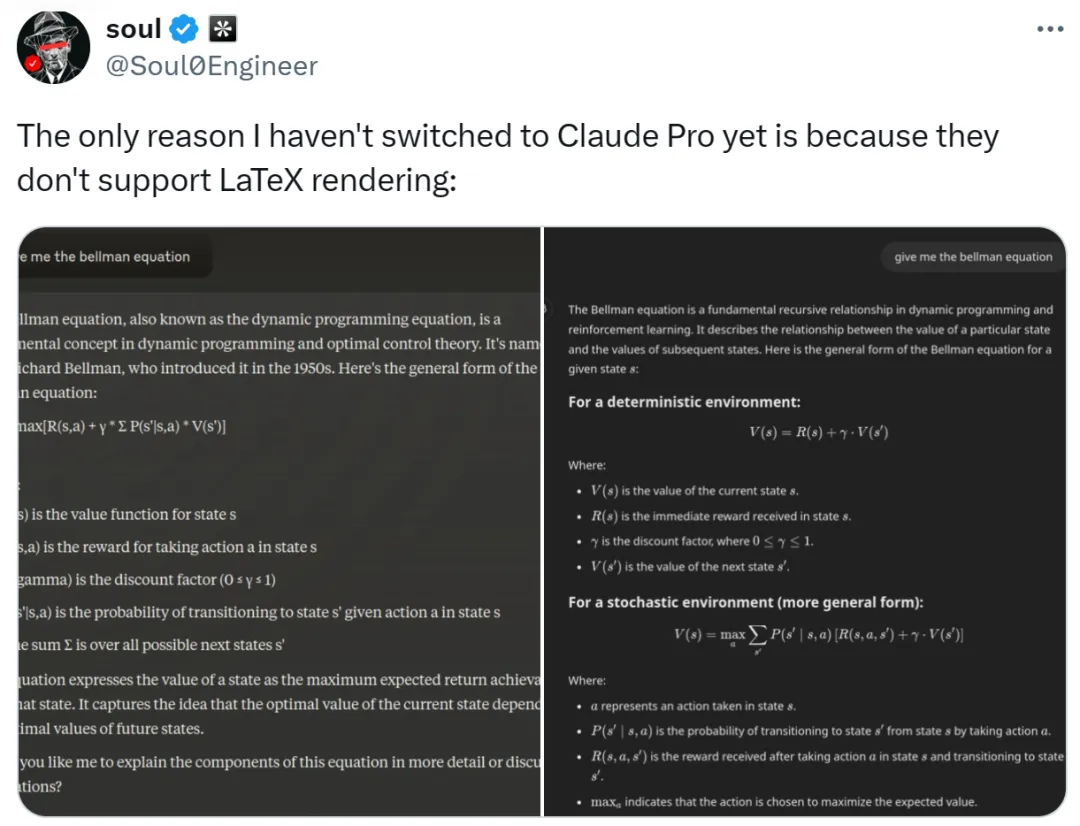
当 ChatGPT 老早就支持使用 LaTeX 语言输入和显示数学公式时,Claude 现在终于补上了这一功能。

随着大模型研究的深入,如何将其推广到更多的模态上已经成为了学术界和产业界的热点。最近发布的闭源大模型如 GPT-4o、Claude 3.5 等都已经具备了超强的图像理解能力,LLaVA-NeXT、MiniCPM、InternVL 等开源领域模型也展现出了越来越接近闭源的性能。
xAI 今天宣布推出 Grok-2 和 Grok-2 mini 测试版,官方说,它的表现比 Claude 3.5 Sonnet 和 GPT-4-Turbo 更好。

把Llama 3.1 405B和Claude 3超大杯Opus双双送进小黑屋,你猜怎么着——

大模型格局,再次一夜变天。Llama 3.1 405B重磅登场,在多项测试中一举超越GPT-4o和Claude 3.5 Sonnet。史上首次,开源模型击败当今最强闭源模型。小扎大胆豪言:开源AI必将胜出,就如Linux最终取得了胜利。